Kennen Sie das? Dienstagnachmittag, Sie sind mitten im Code, bauen diese „simple" ETL-Pipeline für die neue Datenquelle. Freitag? Immer noch am Debuggen.
Wieder mal Stunden an einer Datenpipeline verbrannt? Sie sind damit nicht allein — und genau dafür haben wir eine Lösung gebaut.
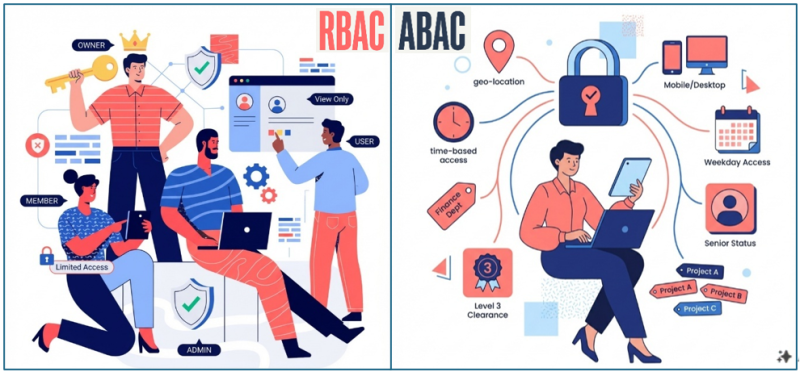
Pipeline-Frust, den jeder kennt!
Sprechen wir die üblichen Übeltäter an. Diese fünf Probleme kennen Data Engineers in jedem Unternehmen — egal ob Startup oder Konzern:
Manuelles Coden für jede neue Anforderung
Neue Datenquelle? Fang von vorne an.
Andere Transformationslogik? Schreib alles neu. Es ist wie im Film „Und täglich grüßt das Murmeltier", nur mit mehr YAML-Dateien. Jede Pipeline ist eine Insel — kein gemeinsamer Kern, keine Wiederverwendung.
Kein standardisierter ETL-Prozess
Sarah schreibt ihre Pipelines so, Tom macht es anders.
Und der neue Freelancer? Viel Glück beim Verstehen seines Ansatzes. Code-Reviews werden zu archäologischen Ausgrabungen. Was früher zwei Stunden dauerte, kostet jetzt zwei Tage.
Entwicklung zieht sich endlos
Was in Tagen erledigt sein sollte, dehnt sich auf Wochen aus.
Sprint-Ziele? Eher Sprint-Vorschläge. Der Backlog wächst, während Sie noch mit den Basics kämpfen. Die Business-Seite wartet — und verliert das Vertrauen.
Fehler, die sich verstecken und teuer werden
Ein Null-Pointer hier, ein Schema-Mismatch da.
Plötzlich ist Production um 3 Uhr morgens down und alle Wochenendpläne sind dahin. Das ist nicht nur nervig; das ist teuer. Und es wäre mit einem soliden Template-Fundament vermeidbar gewesen.
Tool-Wildwuchs und Prozesschaos
Airflow hier, Custom-Scripts da, dort ein Excel-Makro, das „einfach funktioniert".
Du hast längst den Überblick verloren, was wo läuft. Und Dokumentation? Welche Dokumentation? Ein Zoo von Tools ohne gemeinsame Sprache.
Kostenlose Erstberatung
Hören Sie auf, Zeit zu verbrennen — wir bauen das für Sie.
In einem 30-minütigen Gespräch zeigen wir Ihnen, wie unser Template in Ihrer konkreten Umgebung funktioniert — und wie schnell Ihr Team damit produktiv wird.
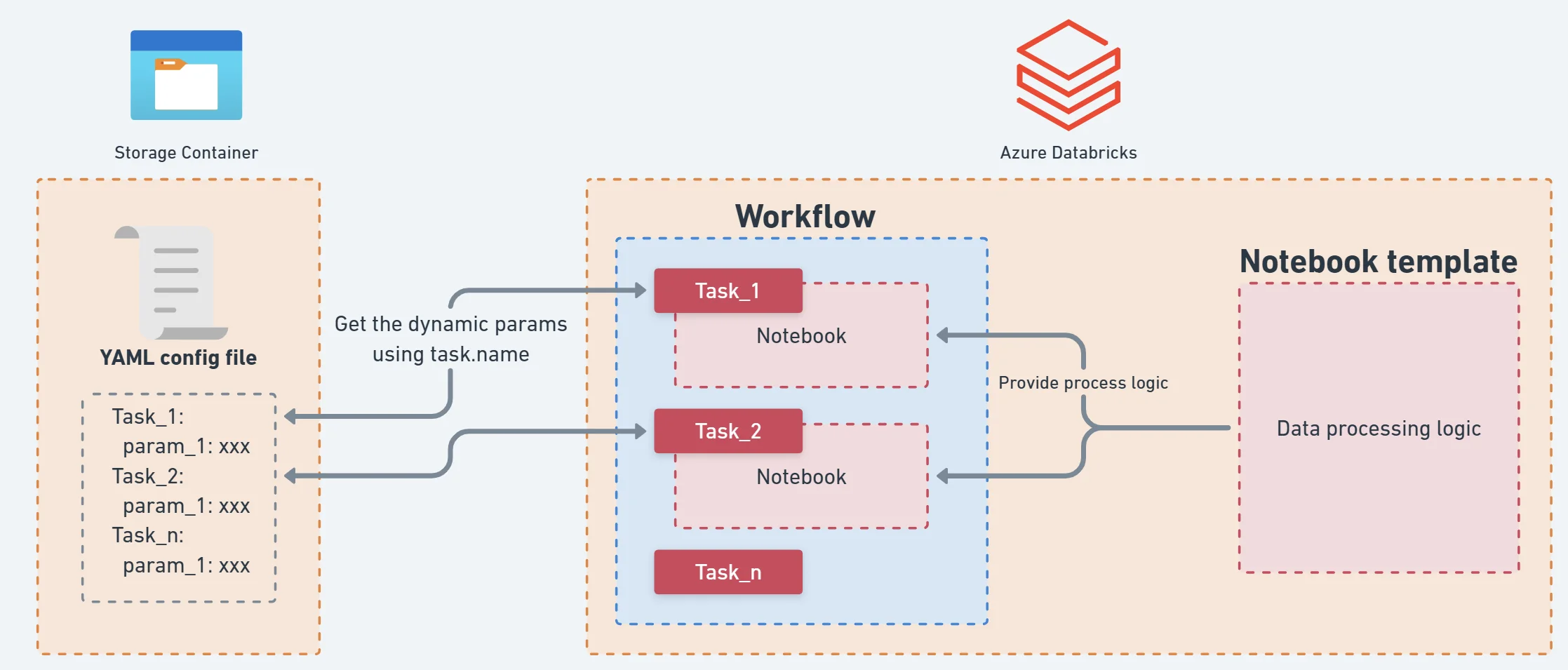
Unser modulares Databricks-Template – die Lösung
Wir dachten uns: Das geht besser! Eine Lösung, die Ordnung ins Datenchaos bringt — eine einzige, solide Basis, auf der jede Pipeline aufbaut.
Unser modulares Databricks-Template bietet:
-
Standardisierte, wiederverwendbare Bausteine Einmal definiert, überall nutzbar — von der Ingestion bis zur Transformation.
-
Schnellere Entwicklung durch vorgefertigte Module Neue Pipelines entstehen in Stunden statt Wochen — bewährt, getestet, einsatzbereit.
-
Bessere Wartbarkeit und Skalierbarkeit Einheitliche Strukturen bedeuten: Jeder im Team versteht jede Pipeline auf Anhieb.
-
Weniger manuelle Fehlerquellen Validierung, Fehlerbehandlung und Logging sind eingebaut — kein Vergessen mehr.
-
Mehr Zeit für das, was wirklich zählt: Innovation Wenn die Infrastruktur läuft, kann Ihr Team sich auf echte Wertschöpfung konzentrieren.
Einmal bauen — immer wieder nutzen. Das ist unsere Philosophie für moderne Datenpipelines auf Databricks.
Passend dazu: Genau diese Arbeitsweise steckt in unserem DIC Lakehouse Accelerator – Teil unserer Leistung Data Platform Engineering.